








在《如何优化非序列光学系统》中,我们介绍了OAS非序列优化模块的操作流程,本文对其进行补充,着重对非序列优化中优化方法的原理进行说明。
简介
在非序列模式下优化光学系统通常比在序列模式下的优化更复杂、更耗时。该文章详细介绍了非序列优化模块的功能,其中我们发现所有的非序列评价函数必须在计算性能目标之前清除探测器和光线追迹,这个过程经常是重复且容易出错的,通常通过OAS非序列优化实现。该功能支持创建常见类型的评价函数。本文将详细讨论如何使用非序列优化。
非序列优化
很多非序列系统有着共同的性能目标,如光通量、均匀性、最大光通量或聚焦等。OAS为用户提供了一种快速创建由常用评价目标组成的评价函数的工具。在菜单栏的优化中就能找到非序列优化模块,任意点击一个功能即可打开优化对话框。
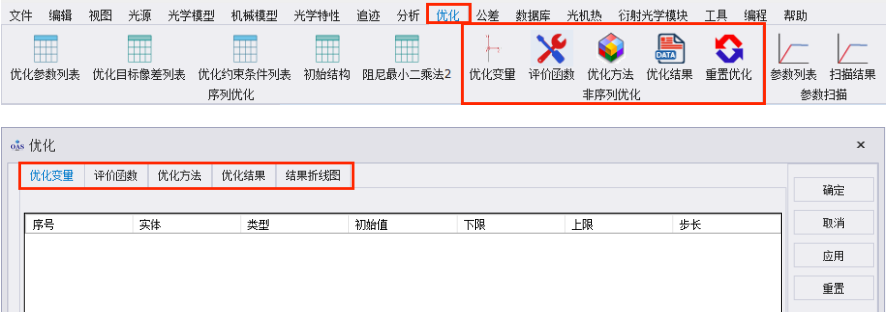
优化变量
此对话框用于设置优化变量。必须至少定义一个变量才能进行优化。对应优化的平面也得勾选光点计算。实体从下拉菜单选择任意需要优化的表面或曲线,类型中选择对应面型需要优化的参数,初始值为类型中所选变量的当前值,然后给定变量的下限和上限,最后给定步长。
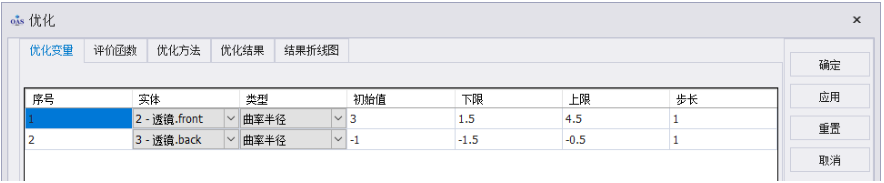
在对话框右侧点击重置即可重置所有数据,需要注意的是,点击重置时,将弹出“是否清除优化所有数据,包括优化参数,评价函数,优化方法,优化结果”的提示,点击“是”将清除所有数据。
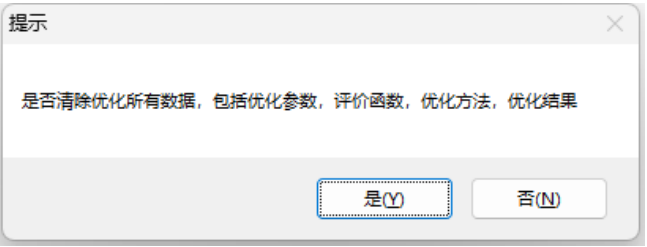
评价函数
此对话框用于设置优化的评价函数目标。实体依旧从下拉菜单选择任意表面或曲线,在优化项选择需要优化的目标,包括:全部半径、偏差、全部通量、角度RMS、半径X、半径Y、半径Z,然后设置评价函数的权重值和目标值即可完成评价函数的设置。

优化方法
设置优化算法。包括遗传算法、粒子群算法、模拟退火算法、差分进化算法、子复合单纯形算法和PRIMA。
遗传算法
遗传算法是模仿达尔文进化从而设计出的一种算法。达尔文进化本质为种群中个体通过变异/遗传/选择,从而实现种群中个体对环境更加适应。其中基因层面的交叉、突变维持了种群中个体样本的彼此不同,适应环境的个体更有将性状遗传给下一代,物种因此变得更加适应生存环境。遗传算法模拟该过程,创建初始种群后,每轮进化过程中都对种群个体进行转码、交叉与变异,解码和评估,从而创建下一代种群(种群中的最优解将会是 我们的候选解)。在算法产生的“种群”内,更优的个体(解)有更多的机率被选择,并将其特征传给下一代种群。这样随着代际更新,候选解可以更好地解决当前问题。
遗传算法流程:
·以初始个体为样本,对各维度数据进行随机扰动,生成一个种群old。
·将各个体的各维度数据进行编码。(即:将各维度数据视为性状,通过编码得到染色体。编码方法多样)
·个体间编码数据(染色体)进行交叉、变异运算,产生新个体。突变模式共有 以下六种:
1.随机突变, 固定突变率pmut。
2.随机突变, 突变率pmut由 fitness差控制。
3.随机突变, 突变率pmut由模长控制。
4.蠕性突变, 固定突变率pmut。
5.蠕性突变, 突变率pmut由fitness差控制。
6.蠕性突变, 突变率pmut由模长控制。
其中使用较多的是 策略 2.
·对新个体的染色体进行解码,得到新种群 new。
·使用新(new)旧(old)两个种群适配不同的策略得到本轮进化生成的子种群。共 有三种适配策略:
1.代际更替:使用新种群完全替代旧种群,但是保留旧种群最优个体,进而得子种群。
2.稳态随机替换:使用新种群最优个体淘汰旧种群最差个体,用该改进旧种群得子种群。
3.稳态淘汰替换:使用新种群最优个体随机淘汰旧种群一个体,用该改进旧种群得子种群。
·生成子种群, 计算子种群评估函数,对于符合条件的个体进行保留,从而迫使 种群最优点往评估函数降低的方向进行转移。
遗传算法参数介绍:
·种群大小:
每一轮进化中,需要对种群内所有个体计算评价函数。 种群越大,每轮进化评价函数计算次数越多,计算量越大, 每一轮消耗的时 间越长; 但较大种群差异越多,即在限定空间中搜寻范围越大,每一轮的寻优能力越 强(指搜寻最值点,而非极值点)。 通常为了较快的收敛,种群大小一般设定为 20-80 之间。
·最大迭代次数:
控制评估函数的计算次数,【计算次数 = 种群 * 当前迭代(进化)次数】。 当优化不收敛时,为防止程序无休止的运行下去,设置最大迭代次数从而使程序能及时跳出。该项对搜寻能力无影响。通常为了节省计算时间,最大迭代次数一般设定为 1000-6000 之间。若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大迭代次数再尝试改变种群大小。
·突变模式:
该项在上文流程介绍中有过阐述。使用较为广泛的突变模式为策略2。
·繁殖模式:
该项在上文流程介绍中有过阐述。该项对优化影响较大,其中策略 3 较于其他策略有更强的收敛能力。
·收敛容差&收敛次数:
当前后两种群的最优个体的评估函数值差异小于收敛容差时,则认为本轮进 化弱收敛。当连续达到收敛次数次弱收敛,则认为程序收敛。 为了达到较好收敛精度,收敛容差一般取 1e-6 到 1e-8,收敛次数设置为 8 到 20 区间内任意整数
粒子群算法
粒子群算法通过大量无质量粒子群来模拟鸟群,仿真鸟群的搜寻食物过程。 粒子具有两个属性:速度和位置。速度代表粒子接下来的移动方向,位置代表粒子当前位置。每个粒子在搜索空间中单独的搜寻最优解,并将其记为当前个体极值,并将个体极值与整个粒子群里的其他粒子共享,种群确定最优个体极值作为整个粒子群的当前全局最优解,粒子群中的所有粒子根据原本移动方向v,当前个体极值和粒子群当前全局最优解来调整自己的速度,进而更新位置。粒子群算法(min)本质是信息的实时共享,是结构上最简单的全局寻优算法。
粒子群算法流程:
·在约束范围内随机产生粒子群(np),所有粒子具有随机方向和位置,并计算所 有粒子的评估函数值,此时设置每个粒子的个体极值为该评估值。
·在种群中确定最优个体极值作为整个粒子群的当前全局最优解。
·粒子群中的所有粒子根据原本移动方向v,当前个体极值和粒子群当前全局 最优解 来调整自己的速度,进而更新位置(注意方向并非直接朝向最优粒子方 位移动)。
·粒子群更新位置,并计算新位置下的粒子的评价函数值。每个粒子比较前后两 次位置下的评价函数,将更优的评价函数及对应位置保存为个体极值(pBestLoc, pBestVal), 并在将个体极值共享,挑选最优个体极值为整个粒子群的当前全局 最优解(gBestLoc,gBestVal)。
判定gBestVal是否符合迭代终止条件,不符合则重复最后两个步骤。
粒子群算法参数介绍:
·种群大小(粒子群大小):
每一轮进化中,需要对种群内所有个体计算评价函数。 种群越大,每轮进化评价函数计算次数越多,计算量越大, 每一轮消耗的时间越长; 但较大种群差异越多,即在限定空间中搜寻范围越大,每一轮的寻优能力越 强(指搜寻最值点,而非极值点)。通常为了较快的收敛,种群大小一般设定为 20-80 之间。
·最大迭代次数:
控制评估函数的计算次数,【计算次数 = 种群 * 当前迭代(进化)次数】。 当优化不收敛时,为防止程序无休止的运行下去,设置最大迭代次数从而使程序能及时跳出。该项对搜寻能力无影响。通常为了节省计算时间,最大迭代次数一般设定为 1000-5000 之间。若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大 迭代次数,再尝试改变种群大小。
·收敛容差&收敛次数:
当前后两种群的全局最优评估函数值gBestVal差异小于收敛容差时,则认 为本轮进化弱收敛。当连续达到收敛次数次弱收敛,则认为程序收敛。为了达到较好收敛精度,收敛容差一般取 (1e-6) 到 (1e-8),收敛次数设置为 8 到 20 区间内任意整数。
模拟退火算法
模拟退火算法来源于固体退火原理,是一种基于概率的算法。将固体加温至 充分高的温度,再让其徐徐冷却,加温时,固体内部粒子随着升温变为无序状, 内能增大某分子和原子越不稳定。而徐徐冷却时粒子渐趋于有序,能量减少,原 子越稳定。在降温过程中,固体在每个温度都达到了平衡态,最后在常温时达到 基态,内能减为最小。
模拟退火算法从某一较高初温出发,伴随温度参数的不断下降,结合概率突 跳特性在解空间中随机寻找目标函数的全局最优解,即在局部最优解能概率性的 跳出并最终趋于全局最优。模拟退火算法是通过赋予搜寻过程一种时变且最终趋 于零的概率突跳性,从而可有效避免陷入局部极小并最终趋于全局最优的串行结 构优化算法。
模拟退火算法分外(退火)循环和内(突跳搜寻)循环两部分。内:在每次退火后的温度下都进行突跳寻优(Metropolis 准则)。外:统筹退火过程中所有温度下的寻优值,接受该值为全局最优解。
模拟退火算法流程
·设置初始温度,退火系数。
·(外循环)确定温度,确定分子初始位置,计算该位置评价函数值。
·(内循环)对分子进行扰动,更新扰动后位置。计算新位置下的评估函数值。若评价函数降低,则接受扰动后位置为粒子新位置。若评价函数升高或不变,则使用Metropolis准则判定是否接受扰动后位置为新位置
·重复内循环过程,直到达到设定的循环次数
·降温,重复 2、3、4 过程。保留每个温度下的最优解,依此判定是否收敛。
模拟退火算法参数介绍
·温度&温度下降因子:
用于退火过程。退火过程为【温度*温度下降因子】。 由上文介绍的Metropolis 准则可了解到,温度越高,算法对突跳点的接受能力越强;当温度逐渐趋于零时,算法算法对突跳点的接受机率小的可怜,几乎拒绝了所有的突跳点。因此,温度应该选的足够高,且下降因子不能过低,以尽可能接受更多的突 跳状态,进而获得高质量解的概率越大,但相应的优化耗时越长。初始温度建议为 5-15 在计算资源允许的情况下,建议温度下降因子取 (0.7,0.9) 区间内数据,以接受更多高质量解。若计算资源有限,则建议取(0.3,0.7)区间内数据,以尽快达到局部收敛 简而言之,温度下降因子区间为[0.3,0.9], 因子越大,全局寻优能力越强,建议默认启用0.7。
·步长扰动模式:
在每次退火的内循环中对粒子的扰动方式。一般默认为策略 1 即可
·最大扰动次数:
控制评估函数的计算次数,当优化不收敛时,为防止程序无休止的运行下去, 设置最大迭代次数从而使程序能及时跳出。该项对搜寻能力无影响。通常为了节省计算时间,最大迭代次数一般设定为 10000。若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大 迭代次数,再尝试改变温度。
·收敛容差&收敛次数:
退火过程中,前后两温度下的最优评价函数值差异小于收敛容差时,则认为 本轮进化弱收敛。当连续达到收敛次数次弱收敛,则认为程序收敛。为了达到较好收敛精度,收敛容差一般取 1e-6 到 1e-8,收敛次数设置为 5 到 20 区间内任意整数
差分进化算法
差分进化算法源于Pikaia遗传算法,差分进化算法摒弃了Pikaia遗传算 法中数据的编码、解码的繁复过程,改为在各维度数据上直接进行操作。差分进化本质和遗传算法没有分别,都是通过控制种群的变异从而使种群中 最优个体更加靠近极值点。
差分进化算法流程
·将初始个体各维度(n)数据进行随机扰动,产生种群 popold(np)。
·计算种群评估函数值,将最优点单独挑出,生成一个完全由最优个体复制的大 小为np的种群bm。
·将原种群复制得到五个复制种群 pm1、pm2、pm3、pm4、pm5,将五个种群中个 体顺序完全打乱。
·通过以下物种方式生成新种群:
方法 1:DE/best/1 ui = bm + fv * (pm1 - pm2) ui = popold * mpo + ui * mui
方法 2:DE/rand/1 ui = pm3 + fv * (pm1 - pm2) ui = popold * mpo + ui * mui
方法 3:DE/rand-to-best/1 ui = popold + fv * (bm-popold) + fv * (pm1 - pm2) ui = popold * mpo + ui * mui
方法 4:DE/best/2 ui = bm + fv * (pm1 - pm2 + pm3 - pm4) ui = popold * mpo + ui * mui 方法 5:DE/rand/2 ui = pm5 + fv * (pm1 - pm2 + pm3 - pm4) ui = popold * mpo + ui * mui
其中,mpo/mui/fv 是一些设定好的记忆因子
·生成新种群ui,计算新种群评估函数,对于符合条件的个体进行保留,从而迫使种群最优点往评估函数降低的方向进行转移。
差分进化算法参数介绍
·种群大小:
每一轮进化中,需要对种群内所有个体计算评价函数。种群越大,每轮进化评价函数计算次数越多,计算量越大,每一轮消耗的时间越长;但较大种群差异越多,即在限定空间中搜寻范围越大,每一轮的寻优能力越强(指搜寻最值点,而非极值点)。通常为了较快的收敛,种群大小一般设定为20-80之间。
·最大迭代次数:
控制评估函数的计算次数,【计算次数 = 种群 * 当前迭代(进化)次数】。当优化不收敛时,为防止程序无休止的运行下去,设置最大迭代次数从而使 程序能及时跳出。该项对搜寻能力无影响。通常为了节省计算时间,最大迭代次数一般设定为 1000-6000 之间。若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大迭代次数,再尝试改变种群大小。
·差分策略:
该项的具体介绍见前文-生成新种群的方式。策略 6-10 与策略 1-5 区别在于生成新种群时,改变是随机的还是集中在某一区域。目前比较优秀的差分策略为 策略1和 策略3。(补充:该项可视为Pikaia遗传算法中突变模式及繁殖模式的结合)
·收敛容差&收敛次数:
当前后两种群的最优个体的评估函数值差异小于收敛容差时,则认为本轮进 化弱收敛。当连续达到收敛次数次弱收敛,则认为程序收敛。 为了达到较好收敛精度,收敛容差一般取 1e-6 到 1e-8,收敛次数设置为 8 到 20 区间内任意整数
子复合单纯形算法
子复合单纯形法是Nelder-Mead单纯形法的改进版,子复合单纯形在问题维度较低时即为Nelder-Mead单纯形算法。当问题维度较高,subplex单纯形法通过将问题各维度划分为一个个子区间,在每个子区间使用单纯形算法,最终将每个子区间(子维度)上的最优值综合,得到整个问题的新最优解;若不符合收敛条件,则重复上面操作。
子复合单纯形算法流程
所谓n维空间的单纯形,指在n维空间中由(n+1)个顶点构成的简单图形或多面体,例如在二维平面中的单纯形应该具有三个顶点(三角形);三维空间中的单纯形 应该有四个顶点(四面体)。 单纯形的基本思想为:
1.选定 n+1 个顶点构成初始单纯形,计算并对各顶点目标函数值排序;
2.确定函数值最大点(最坏点x_worst),及其他所有点生成的重心x_gravity;
3.通过重心x_gravity将最坏点 x_worst 进行反射,得到新的反射点 x_ref ;
4.计算新的反射点评估函数值,新点评估函数值影响下步计算:
X_New : 新点
X_Low : 旧点集的最优点
X_Worst : 旧点集的最差点(被反射点)
X_Second : 剔除最差点的旧点集的最差点,也即旧点集中第二坏点
X_Zip : 压缩后的点
X_Gravity : 重心
X_Ref : 反射点

若压缩失败,整个单纯形以x_low为顶点进行收缩(只保留 x_low, 单纯形中其他所有点与x_low的距离减半)
·通过单纯形内点的评估函数,或点与点之间的距离进而判定优化是否继续进行, 若未达收敛条件,则在新单纯形中重复2、3、4步骤。
子复合单纯形法参数介绍
·收敛容差Subplex子复合单纯形的收敛容差和其他算法的收敛容差略有不同。Subplex算法用于判定收敛(find min)的条件是所有子空间单纯形中x_low和x_worst的二范数小于收敛容差。简单的说,就是当前单纯形中距离最远的两点 间距离非常小。为了展现收敛能力,收敛容差一般设为(1e-6)。若想要更高精度,令收敛容差更加趋近0即可。
·最大迭代次数:启动子复合单纯形进行优化时,若优化不收敛,为防止程序无休止的运行,设置最大迭代次数从而使程序能及时跳出。该项对搜寻能力无影响。 通常为了节省计算时间,最大迭代次数一般设定为1000。若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大迭代次数。
·扰动步长:为了方便处理单纯形在各维度上的超界问题,将单纯形点的维度上下限统一约束到[0,1]内。算法中由初始点以扰动步长在n个维度上扰动,生成n个扰动点,加上初始点(即为 n+1 个点)构成单纯形。因此扰动步长不建议大于 0.5,这样会导致扰动点全在边界上,影响初轮单纯形计算。建议取[0.1,0.3]间的任意实数。
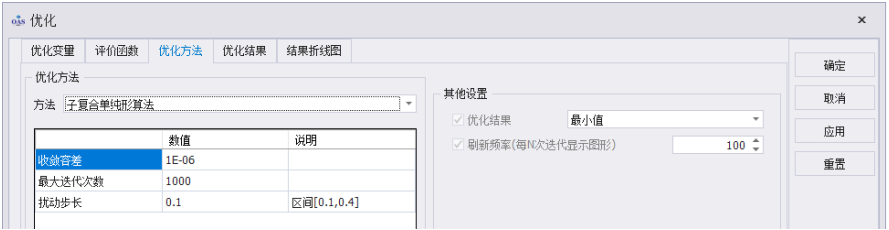
PRIMA
PRIMA又叫Powell信赖域法,其核心思想如下:
设优化的问题评价函数为 f(x), 该问题初始点为 x0, 则
1.在以当前迭代点 x0 为中心的一个闭球(信赖域)内,将 f(x)泰勒展开, 使用二次函数 m(d) 近似 f(x), d = x - x0 。
2.在该信赖域内,对 m(d) 使用截断共轭梯度法求解该二次函数极小化子 问题。
3.令 p = ( f(x) - f(x+d) ) / ( m(x) - m(x+d) ) , 若 p 较大,则认为 m(x) 在 x 处近似 f(x) 较好,更新 xnew = x+d, 且若 d 延伸到信赖域边界,下次信赖域设定时增加信赖域半径(通常是乘以 一个大于 1 的常数); 若 p 较小(甚至为负),则说明二次函数 m(d)的近似不够可靠,需要缩 小信赖域半径,重新计算极小值。
4.反复进行 步骤 2、步骤 3,直到符合收敛条件。
信赖域内的梯度共轭法表述较为麻烦,但该算法是局部优化典型算法之一, 在网络上可轻而易举获得相关介绍,在此不多赘述。
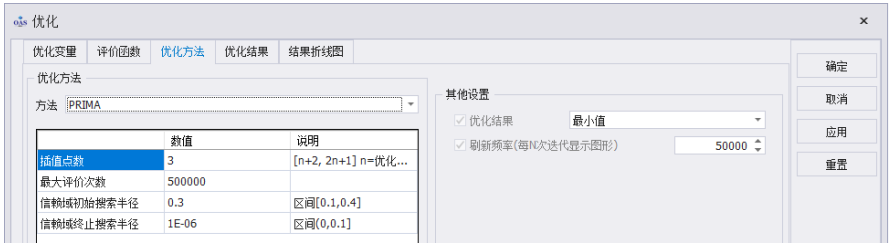
PRIMA参数介绍
·插值点数:
通过插值点对信赖域内某点 x 进行差分,进而计算出该点的一阶导及二阶 导,从而得到近似函数 m(d)。
·最大评价次数:
控制评估函数的计算次数,当优化不收敛时,为防止程序无休止的运行下去, 设置最大迭代次数从而使程序能及时跳出。该项对搜寻能力无影响。 通常为了节省计算时间,最大迭代次数一般设定为 10000。 若程序在达到最大迭代次数后不收敛(未达到心理预期),则应首先增大最大 迭代次数。
·信赖域初始搜寻半径 & 信赖域终止搜寻半径:
Powell 信赖域法在计算之初就将问题的各维度上下限约束到 [0,1] 上,因 此应有 2*初始搜寻半径 < 1.0。建议使用 0.2 左右即可。
若信赖域算法运行收敛到极小值,在极小值的信赖域中进行搜寻不会再令评 估函数下降,因此会逐渐收缩信赖域半径。
故而,信赖域终止半径即起着判定 Powell 信赖域法是否收敛的作用,似收敛容差。
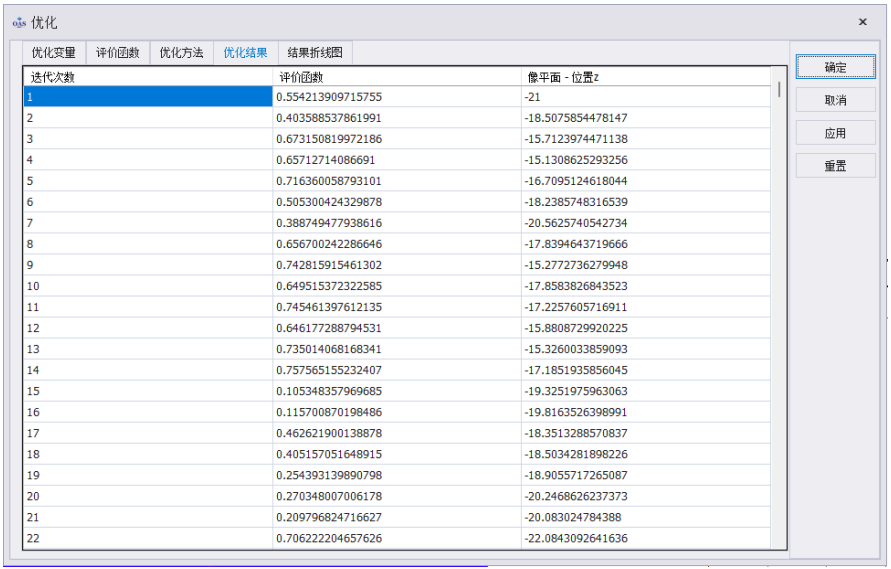
优化结果
设置完优化变量、评价函数和优化方法后点击确定开始优化,在另一篇文章《如何优化非序列光学系统》中,介绍了施密特望远镜位置优化,该案例针对像平面的“位置z”进行了优化,前后的对比如下:


优化前像平面的位置z为-21mm,优化后为-19.547393655650545mm,实现了该光学系统的聚焦。
在优化对话框中可以查看其优化结果和结果折线图:
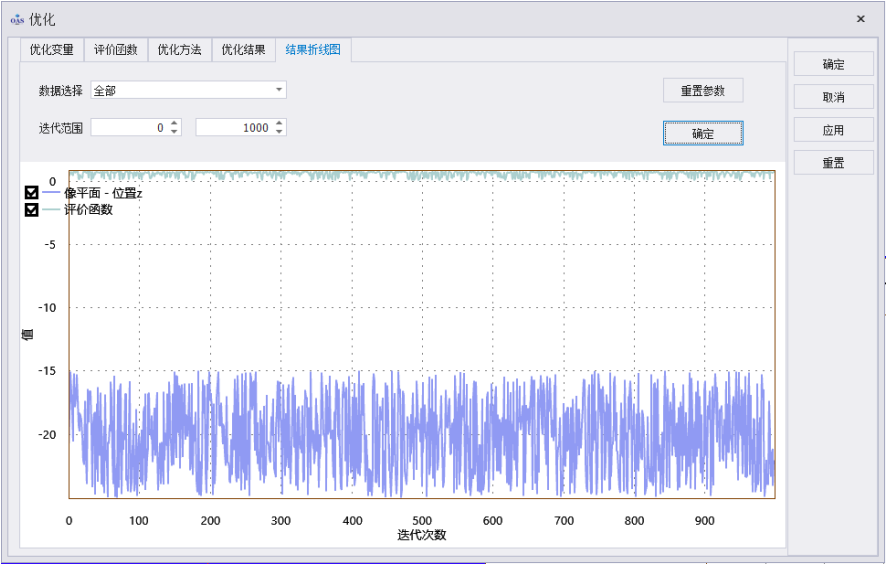
在结果折线图中选择需要查看的数据以及迭代范围,数据选择包含了在优化变量和评价函数中设置的所有参数,迭代范围不超过在优化方法中设置的迭代次数,然后点击确定即可生成折线图,点击重置参数可重置结果折线图。